然而,由于越南语具有声调符号和手写文字的特殊性,识别问题并不仅仅停留在“识字”层面,而是需要具备对语言语境和文档版式的深度理解能力。
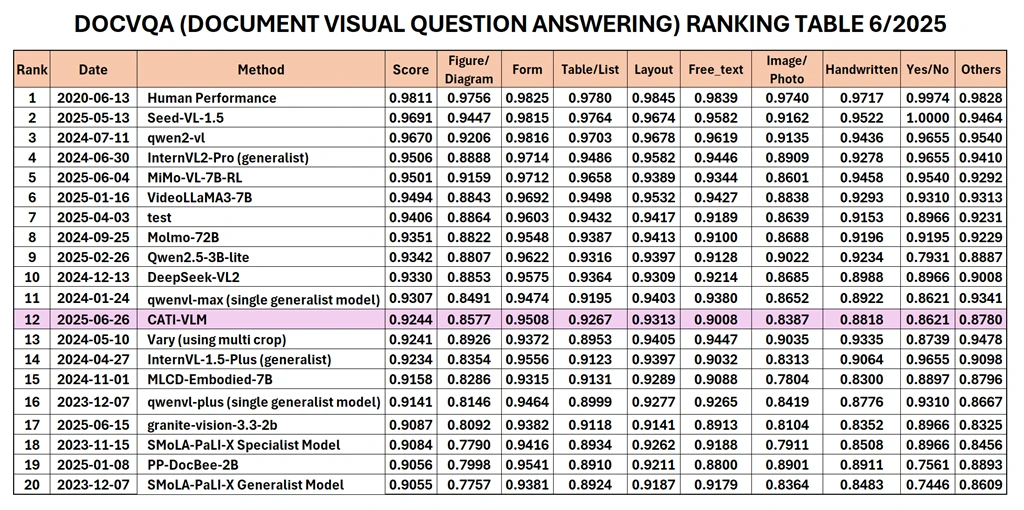
近日,CMC技术应用研究院(CMC ATI)正式发布其视觉文档理解模型CATI-VLM,该模型基于5TB大数据库开发而成。在2025年6月由“强健阅读竞赛”(Robust Reading Competition, RRC)公布的文档视觉问答(Document Visual Question Answering, DocVQA)排行榜中,成功跻身全球前12名,并位居越南第一。
RRC是全球计算机视觉与文本识别领域最具声望的科学竞赛之一,由西班牙巴塞罗那自治大学(UAB)计算机视觉中心(CVC)于2011年创办,吸引来自清华大学、现代汽车集团、腾讯等诸多知名研究机构、大学和科技企业的积极参与。
尽管仅使用了30亿参数,CATI-VLM在RRC排行榜中的7个数据集里有4个取得了最高准确率,超越了来自大型科技公司的许多模型,如Deepseek(参数量达270亿)、GPT-4 Vision Turbo结合Amazon Textract OCR(排名第34)、以及百度模型(排名第22)。这一成绩充分展现了CATI-VLM在模型优化方面的卓越能力,成功实现了计算效率与准确率之间的平衡,符合越南当前的技术基础设施条件。
CMC科技集团董事长兼执行主席阮忠正表示,这一成就是该集团十余年来坚持不懈投入研究与开发的成果,充分体现了掌握越南自主科技的战略方向,并紧密结合人工智能转型与迈向全球的发展目标。阮忠正先生强调:“我们相信,越南的智慧完全有能力与全球科技巨头比肩,在世界科技版图上占据应有的地位。”(完)
来源:越通社